Sai số trong nghiên cứu khoa học nói chung (bias, error) được định nghĩa là bất kì một tác động nào trong bất kì giai đoạn nào của cuộc điều tra hay phiên giải số liệu, thông tin/ suy luận thống kê mà gây ra sự sai trệch có hệ thống đối với kết quả thật [1].
Trong quá trình thực hiện một nghiên cứu nói chung ta gặp rất nhiều sai số, chúng tác động tới kết quả nghiên cứu (KQNC), làm sai chệch kết quả này có thể theo chiều hướng tăng lên hay giảm đi.
Trong các bài ở kì đăng tải trước, ít nhiều chúng ta đã động chạm tới một số sai số, đặc biệt sai số ngẫu nhiên. Trong bài này chúng ta hệ thống lại các sai số và đi sâu thêm vào một số sai số hay gặp.
Theo nhiều tài liệu hiện nay, người ta thường chia thành hai nhóm lớn sai số: Sai số chọn và sai số hệ thống. Mỗi nhóm lại gồm nhiều sai số khác nhau.
1.Sai số chọn (selection bias)
Sai số chọn hay là sai số chọn mẫu là sai số xuất hiện làm cho mẫu không thể đại diện cho quần thể mà từ đó mẫu được rút ra. Sai số chọn lại gồm nhiều loại khác nhau.
1.1.Sai số ngẫu nhiên: Sai số ngẫu nhiên là do các yếu tố may rủi xen vào kết quả, nó liên quan đến biến thiên của mẫu và cỡ mẫu [4].
Trong bài Mẫu và phương pháp chọn mẫu trong nghiên cứu y học đã đăng ở kì trước, chúng ta đã biết, lý tưởng nhất là nghiên cứu toàn bộ quần thể, tức là tất cả các đối tượng của quần thể nghiên cứu được xem xét hết, không trừ đối tượng nào. Nếu như vậy thì toàn bộ sai số ngẫu nhiên không còn nữa. Kết quả nghiên cứu có độ chính xác cao (tuy nhiên vẫn còn sai số không ngẫu nhiên). Tức là khi nghiên cứu toàn bộ quần thể ta được kết quả của toàn quần thể rồi, và như vậy không dùng các phép ngoại suy, nói cách khác không dùng các trắc nghiệm thống kê nữa. Nếu dùng, sẽ dẫn đến sai.
Ví dụ, tại một nghiên cứu thí điểm đưa khám chữa bệnh cho người có thẻ bảo hiểm y tế (BHYT) từ bệnh viện huyện (BVH) về các trạm y tế xã, tác giả đã thống kê được số lần điều trị nội trú trung bình/thẻ/ năm như biểu đồ 1.
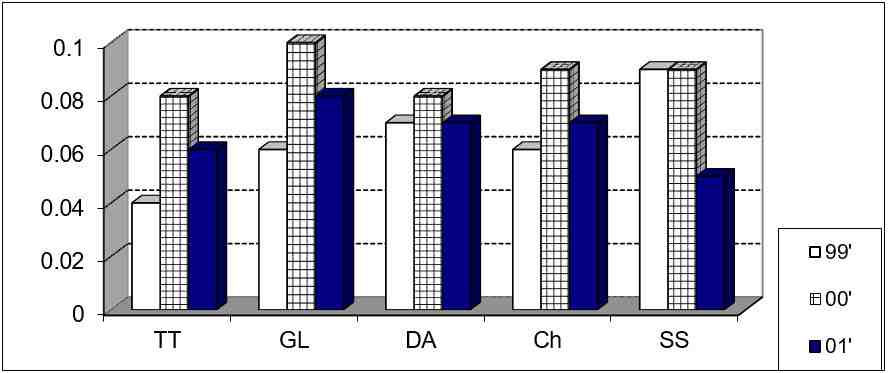
Biểu đồ 1. Số lần điều trị nội trú/thẻ BHYT / năm, tại 4 BVH
Từ biểu đồ 1 tác giả nhận xét: Số lần điều trị nội trú/một thẻ BHYT (chung các loại thẻ)/năm tại BVH Sóc Sơn (SS, là nơi thực hiện thí điểm) giảm rất mạnh trong thời gian thí điểm [năm 2000 (00’) và năm 2001 (01’)] so với trước thí điểm năm 1999 (99’), ở nhóm chứng (Ch) chỉ số này tăng ít [2]. Tác giả còn so sánh chỉ số này của nơi thí điểm (SS) với các BVH khác, không thực hiện thí điểm là BVH Thanh Trì (TT), Gia Lâm (GL) và Đông Anh (ĐA). Sở dĩ so sánh được như vậy mà không cần dùng trắc nghiệm thống kê (tức không sử dụng giá trị p để ngoại suy) là vì, trong chương 2, về phương pháp nghiên cứu, tác giả đã thuyết minh rõ đó là các số liệu thống kê cả năm của toàn bệnh viện. Tức là tác giả đã so sánh chỉ số của toàn quần thể nghiên cứu này với chỉ số của toàn quần thể nghiên cứu khác, không có sai số ngẫu nhiên nên không được dùng trắc nghiệm thống kê trong so sánh [2].
Các sai số ngẫu nhiên cũng không xảy ra trong trường hợp sau:
a) Chọn mẫu nhưng theo phương pháp không ngẫu nhiên: Mẫu thuận tiện, mẫu mục đích…
Ví dụ, trong nghiên cứu về hiệu quả của bài thuốc đông y thân thống trục ứ thang (TTTUT) trên lâm sàng. Tác giả chọn 2 nhóm (110 người bệnh, được tính theo công thức mẫu quy định): Nhóm chứng gồm 55 người bệnh được điều trị bằng điện châm + kéo giãn cột sống; nhóm can thiệp cũng gồm 55 người bệnh cũng điều trị bằng điện châm + kéo giãn cột sống và dùng thêm TTTUT. Giữa hai nhóm có sự ghép cặp về tuổi, giới và mức độ tổn thương…Tác giả can thiệp trong 15 ngày và nhận xét kết quả sau can thiệp theo 3 chỉ số (VAS, Schober và Laségue) như sau: “…sự cải thiện VAS, Schober và Laségue đều là rất rõ rệt (p< 0,05)” [3]. Ở đây ta thấy tác giả đã sử dụng giá trị p để so sánh giữa hai nhóm trước – sau can thiệp là không phù hợp, bởi:
- Số lượng 110 người bệnh được chọn theo phương pháp ngẫu nhiên hay không ngẫu nhiên thì không có thông tin. Thực tế cho thấy không chọn theo phương pháp ngẫu nhiên được, mà thường chọn cùng một thời điểm, vì vậy đó là mẫu thuận tiện, không phải mẫu mang tính ngẫu nhiên, nên không sử dụng các trắc nghiệm thống kê ở đây.
- Giả dụ cho rằng số lượng 110 người bệnh này là toàn bộ quần thể nghiên cứu, và chia quần thể này thành 02 quấn thể nhỏ (55 người bệnh/ quần thể nhỏ). Việc so sánh tham số của hai quần thể nhỏ này với nhau đương nhiên không dùng giá trị p vì không còn sai số ngẫu nhiên.
Trên thực tế ta thấy nhiều nghiên cứu lâm sàng và nhiều nghiên cứu thực nghiệm trên động vật chỉ được tiến hành trên một nhóm nhỏ (vài chục người bệnh, vài chục con chuột hay vài chục con thỏ…) nhưng các tác giả vẫn sử dụng giá trị p để suy diễn thống kê, là điều sai lầm lớn vì, như trên đã phân tích, dù theo cách giải thích nào đi nữa thì, đó chỉ là mẫu không ngẫu nhiên hay là một quần thể nghiên cứu nhỏ.
b) Cỡ mẫu nhỏ hơn so với độ lớn tối thiểu (tính được từ công thức mẫu tối thiểu). Ví dụ, theo công thức mẫu cắt ngang ta tính được cỡ mẫu tối thiểu của một nghiên cứu nào đó là 450 người bệnh, nhưng sau khi thu thập số liệu xong, làm sạch và loại bỏ những phiếu khảo sát không đảm bảo, ta chỉ còn ít hơn 450 phiếu (ứng với dưới 450 người bệnh), tức ít hơn so với cỡ mẫu thối thiểu được tính là 450. Trường hợp này NCV cũng không được phép sử dụng giá trị p để ngoại suy vì, cỡ mẫu nhỏ, không có tính đại diện cho quần thể nghiên cứu.
Tóm lại, mẫu không ngẫu nhiên hay cỡ mẫu nhỏ hơn cỡ mẫu tối thiểu đều không cho phép ngoại suy (tức suy luận thống kê- Statistical inference) vì, những mẫu này không đại diện cho quần thể mà từ đó mẫu được rút ra. Tức trong trường hợp này không có sai số ngẫu nhiên.
Như phân tích trên đây, muốn khắc phục sai số ngẫu nhiên, thì có 02 cách:
- Điều tra toàn bộ quần thể nghiên cứu, không trừ đối tượng nghiên cứu nào. Nhưng chú ý rằng, với quần thể có kích thước lớn thì cách làm này khó khả thi hay tốn kém nhiều nguồn lực.
- Nếu không điều tra được toàn bộ quẩn thể nghiên cứu thì ta điều tra theo mẫu, nhưng phải là mẫu được chọn ngẫu nhiên với cỡ mẫu đủ lớn, tức mẫu đó phải đại diện cho quần thể mà từ đó mẫu được rút ra. Dựa trên các tham số của mẫu, NCV có thể ước lượng được tham số tương ứng của quần thể nghiên cứu thông qua suy luận thống kê (tức sử dụng các trắc nghiệm thống kê phù hợp) (xem phần “1.2. Phân tích thống kê suy luận” trong bài “Xử lý và phân tích số liệu cho nghiên cứu định lượng” đã đăng ở kì trước).
1.2. Sai số chọn mẫu, không ngẫu nhiên: Là sai sót xuất hiện trong khi chọn ca bệnh hay chọn đối tượng nghiên cứu do NCV gây ra. Sai số này lại chia thành nhiều loại khác nhau:
a) Sai số không hồi đáp (Non-response bias): Sai sót không lấy được thông tin của toàn bộ đối tượng trong mẫu hay quần thể nghiên cứu,
b) Sai số bỏ cuộc (Drop-out bias): Do mất đối tượng nghiên cứu trong nghiên cứu thực nghiệm, nghiên cứu thực nghiệm lâm sàng hay các nghiên cứu dài hơi (longitudinal survey).
c) Sai số nhập viện (Berksonal bias): Do chỉ điều tra những người nhập viện, người không nhập viện không được điều tra. Ví dụ, nghiên cứu tìm tỉ lệ sử dụng kháng sinh của người bị viêm họng thuộc huyện M năm 2020 chẳng hạn mà chỉ tiến hành điều tra người đến cơ sở y tế thăm khám thì mắc sai số nhập viện, do bỏ sót người không đến cơ sở y tế mà họ cũng bị viêm họng. Một ví dụ khác, nghiên cứu về “hiệu quả của “Doctor SAMAN – Khít khao” trên lâm sàng”, tác giả lấy “cỡ mẫu n=115; từ 15/03/2017– 15/12/2018”, đương nhiên ở đây mắc sai số nhập viện về nhiều khía cạnh:
- Chỉ nghiên cứu được người bệnh là phụ nữ trung tuổi, bị “doãng rộng âm đạo”, đến cơ sở y tế của NCV, bỏ sót người bệnh đến cơ sở y tế khác hay không đến cơ sở y tế nào.
- Chỉ nghiên cứu được người bệnh là phụ nữ trung tuổi, bị “doãng rộng âm đạo”, đến cơ sở y tế của NCV trong khoảng thời gian từ 15/03/2017– 15/12/2018, không nghiên cứu được người bệnh ngoài khoảng thời gian nghiên cứu trên đây…
Nhưng các tác giả của nghiên cứu “Doctor SAMAN – Khít khao” trên lâm sàng” khéo léo “trốn được” sai số nhập viện bằng cách kết luận về kết quả nghiên cứu chỉ “ở 102 case, chiếm 88,69% người tham gia nghiên cứu, với n = 115” trên đây mà không suy diễn kết quả này cho tất cả phụ nữ trung tuổi trong quần thể nói chung [5].
Trong trường hợp không có cách nào tránh được các sai số trên thì, NCV phải chỉ rõ chúng khi bàn luận cho KQNC và đưa ra kết luận một cách khôn ngoan nhất.
2. Sai số thông tin (Information bias)
Người ta định nghĩa sai số thông tin là sai số quy cho những sai sót trong quá trình thu thập, xử lý thông tin hoặc sử dụng công cụ đo lường có tính giá trị thấp, không đo được chính xác đặc tính mà chúng ta muốn đo đạc [1].
Sai số này không do chọn mẫu sinh ra (Non-sample bias), mà có thể do sai sót trong việc thu thập thông tin, mã hóa hay phân tích số liệu…do NCV gây ra.
.2.1. Sai sót của công cụ thu thập thông tin: Bộ câu hỏi, bảng kiểm không đảm bảo, dụng cụ thí nghiệm bị sai chệch, dụng cụ đo lường bị sai số…hay đặt ra thang phân loại không tốt (Misclassification errors)…
2.2. Sai sót khi NCV phỏng vấn, quan sát, chủ trì họp nhóm, lấy số liệu thống kê…sinh ra các sai số quan sát (Observer bias) hay sai số hỏi (Interviewer bias)…[1].
2.3. Các loại sai số khác: Sai số do chọn đối tượng nghiên cứu không đảm bảo vì tiêu chuẩn chọn không đảm bảo hay chọn lẫn. Sai số nói dối, sai số nhớ lại (recall bias) hay xảy ra trong nghiên cứu hồi cứu…
Hiện nay có một loại sai số mà nhiều NCV mắc, đó là đổi biến định tính thành biến định lượng và ngược lại. Ví dụ, trong một nghiên cứu về sự hài lòng của cán bộ y tế hay của người bệnh về dịch vụ khám chữa bệnh (KCB) tại một bệnh viện (xin dấu tên), tác giả sử dụng thang điểm Likert để đo sự hài lòng như sau:
Rất không hài lòng…… ..điểm 1;
Không hài lòng………….điểm 2;
Bình thường……………..điểm 3;
Hài lòng………………….điểm 4;
Rất hài lòng………………điểm 5.
Với thang điểm như trên, tác giả đi phỏng vấn một cán bộ y tế hay một người bệnh X nào đó, tìm sự hài lòng về các khía cạnh khác nhau của dịch vụ KCB, giả dụ:
Về cơ sở vật chất- trang thiết bị cho KCB……điểm 4
Về thuốc cho KCB……………………………điểm 3
Về quy trình bố trí sắp xếp các bước………….điểm 2
Về thủ tục hành chính…………………………điểm 5
Từ kết quả trên tác giả tính điểm trung bình để đánh giá chung:
Điểm trung bình: (4+3+2+5)/4 = 3,5
Việc làm trên đây mắc một sai lầm rất lớn về việc đổi biến định tính (các mức hài lòng) thành biến định lượng, đo đếm được (điểm), vì chúng ta không thể cộng “Rất không hài lòng” (điểm 1) với “Hài lòng” (điểm 4) để thành “Rất hài lòng” (điểm 5) được. Hơn nữa, các mức hài lòng như trên là biến không liên tục (tức không có thập phân) và “điểm” là biến liên tục (có hàng thập phân) nên không quy đổi cho nhau được.
Nếu tác giả dùng “kí hiệu” thì lại được:
Rất không hài lòng…… ..kí hiệu là 1;
Không hài lòng…………. kí hiệu là 2;
Bình thường…………….. kí hiệu là 3;
Hài lòng…………………. kí hiệu là 4;
Rất hài lòng……………… kí hiệu là 5.
Dĩ nhiên, với cách “kí hiệu” trên đây, không được phép làm các phép tính như đối với biến định lượng.
Cách khắc phục sai số thông tin: Tất cả các sai số trên đây đều do NCV gây ra trong mọi khâu của thiết kế nghiên cứu và thực hiện nghiên cứu, do vậy muốn khắc phục được các sai số này, NCV (hay nói đúng hơn là nhóm nghiên cứu) phải có kiến thức, kĩ năng và kinh nghiệm làm nghiên cứu, tuân thủ chặt chẽ các tiêu chuẩn và quy trình nghiên cứu [4].
3. Sai số do nhiễu (confounder)
Sai số do nhiễu xuất hiện trong các nghiên cứu sự tương quan hay kết hợp nhân quả nên nó phải được chú ý đặc biệt trong các thiết kế và phiên giải kết quả.
Như trong bài Viết đối tượng và phương pháp nghiên cứu cho đề tài nghiên cứu khoa học Y học đã đăng tải kì trước, mục 1.8.3. Sai số do nhiễu đã nêu: Sai số do nhiễu (yếu tố phơi nhiễm 1) làm sai lệch mối liên quan giữa yếu tố phơi nhiễm 2 với bệnh, trong khi đó, chính nó là nguyên nhân của bệnh, mà trên thực tế giữa yếu tố phơi nhiễm 2 có thể không liên quan gì đến bệnh cả [6]. Một ý kiến khác cho rằng, nhiễu vừa có mối quan hệ đến bệnh lại vừa có mối quan hệ với yếu tố nguy cơ, trong mối quan hệ nhân quả mà ta khảo sát [4].
Ví dụ, một điều tra ở bang Massachussetts, Hoa Kì cho thấy trẻ sơ sinh của những ông bố hút thuốc thường nhẹ cân hơn trẻ sơ sinh của các ông bố không hút thuốc. Ta nghĩ rằng bố hút thuốc có kết hợp với sơ sinh nhẹ cân, nhưng thực ra ở đây không có mối liên quan nào giữa hai biến: bố hút thuốc – sơ sinh nhẹ cân. Thực tế, nếu bố hút thuốc dễ làm mẹ cũng hút thuốc và chính mẹ hút thuốc mới làm sơ sinh nhẹ cân [1].
Nhiễu thường rất kín đáo, đôi khi khó xác định, đòi hỏi nghiên cứu viên phải có nhiều kinh nghiệm để phát hiện chúng.
Có những nhiễu tiềm ẩn chung cho mọi nghiên cứu phân tích như tuổi, giới, nghề nghiệp, chủng tộc…Mỗi nghiên cứu lại có thể có yếu tố nhiễu riêng như hút thuốc đối với kết hợp café –nhồi máu cơ tim…
Trong thực hành, NCV cần xác định một yếu tố có phải là nhiễu hay không, nếu nó là nhiễu rồi thì xác định độ lớn của nó và xác định cả chiều hướng của nó nữa, gọi là nhiễu dương tính khi nó gây ra ước lượng trội của kết hợp và nhiễu âm tính khi nó gây ra ước lượng non cho sự kết hợp [4].
Có nhiều biện pháp không chế nhiễu khác nhau, tùy loại nhiễu. Sau đây giới thiệu một số biện pháp đơn giản, hay dùng.
3.1. Kĩ thuật ngẫu nhiên hóa
Trong nghiên cứu can thiệp nói chung (nghiên cứu thực nghiệm hay thử nghiệm lâm sàng…), kĩ thuật chọn mẫu ngẫu nhiên và đủ lớn cho cả nhóm can thiệp và nhóm chứng giúp trung hòa được các nhiễu (kể cả nhiễu mà NCV nghi ngờ hay không biết đến). Ví dụ, chúng ta nghiên cứu tác dụng của thuốc A trong điều trị bệnh gout tại quần thể người bị gout thuộc huyện M, giả dụ, giới tính là yếu tố nhiễu, vì nam giới hay uống bia, rượi đi kèm với ăn nhiều thịt nên tỉ lệ điều trị không khỏi gout của nam giới luôn cao hơn nữ giới khoảng 12%. Hơn nữa, giữa thuốc A với giới tính cũng có mối quan hệ vì thuốc này được cho là làm tăng cường khả năng tình dục của nam giới, do vậy hay được phái nam tại huyện M sử dụng.
Ta chọn một mẫu ngẫu nhiên đủ lớn 300 người bệnh gout vào nhóm thử nghiệm và 300 người bệnh gout vào nhóm chứng, biểu thị tại bảng 1:
Bảng 1. Bảng 2x2 thử nghiệm lâm sàng dùng thuốc A chữa gout
|
| Khỏi gout | Không khỏi | Cộng (cỡ mẫu tối thiểu) |
| Nhóm thử nghiệm: Dùng thuốc A | 250 | 50 | 300 |
| Nhóm chứng: Không dùng thuốc A | 20 | 280 | 300 |
| Cộng | 270 | 330 | 600 |
Từ bảng 1 ta tính được nguy cơ tương đối khi so sánh hai nhóm dùng và không dùng thuốc A:
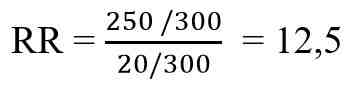
Có nghĩa là người bệnh gout huyện M có dùng thuốc A có khả năng khỏi bệnh gấp 12,5 lần so với người bệnh gout không dùng thuốc A.
Như trên đã nêu, tỉ lệ điều trị không khỏi bệnh gout của nam giới luôn cao hơn nữ giới khoảng 12%, nhưng vì ta chọn ngẫu nhiên người bệnh gout vào cả hai nhóm dùng thuốc A và không dùng nên số nam giới mắc bệnh cũng được chọn ngẫu nhiên vào hai nhóm này do vậy tỉ lệ điều trị không khỏi bệnh gout của nam được “phân phối đều trong hai nhóm”. Chúng bị triệt tiêu khi tính giá trị RR trên đây, nên giá trị RR = 12,5 trên đây không đổi. Chúng ta đã khống chế yếu tố nhiễu do giới tính thành công, thông qua kĩ thuật chọn mẫu ngẫu nhiên.
3.2. Kĩ thuật thu hẹp tiêu chuẩn tham gia nghiên cứu: Kĩ thuật này đơn giản, ít tốn kém và được áp dụng cho mọi thiết kế nghiên cứu. Ví dụ, cũng với nghiên cứu tác dụng của thuốc A trong điều trị bệnh gout trên đây, do có yếu tố nhiễu là giới nên tiêu chuẩn nghiên cứu bị thu hẹp lại: Chỉ nghiên cứu trên nam giới (toàn nam) hay chỉ trên nữ giới (toàn nữ). Kĩ thuật thu hẹp tiêu chuẩn nghiên cứu có một số hạn chế:
-Khó đạt tới cỡ mẫu cần thiết với một lực mẫu trọn vẹn trong khoảng thời gian hợp lý;
-Khả năng tổng quát hóa kết quả nghiên cứu bị hạn chế;
-Không đánh giá được sự kết hợp/tương quan khi chia nhỏ các mức phơi nhiễm và bệnh;
-Tiêu chuẩn không đủ hẹp vẫn không loại trừ được hết nhiễu tiềm ẩn [4].
3.3. Kĩ thuật ghép cặp: Kĩ thuật này có giá trị loại bỏ được nhiễu khá tốt bằng cách chọn các đối tượng vào nghiên cứu sao cho các yếu tố nhiễu tiềm ẩn phân phối đều trong hai nhóm can thiệp (thử nghiệm) và chứng, nhờ vậy nhiễu bị triệt tiêu. Ví dụ, trong nghiên cứu bài thuốc “Thân thống trục ứ thang” của Trần Thái Hà, tác giả đã ghép cặp đối tượng nghiên cứu thuộc hai nhóm người bệnh: Có dùng và không dùng TTTUT về tuổi, giới và mức độ tổn thương [3], do vậy các nhiễu tiềm ẩn thuộc về các yếu tố này đã bị khống chế tốt.
3.4. Kĩ thuật phân tầng: Kĩ thuật này phức tạp và có thể tốn kém trong nhiều trường hợp, nhưng có giá trị phân tích nhiễu khá tốt.
NCV chia quần thể nghiên cứu thành các tầng dựa trên đặc tính của yếu tố nhiễu nghi ngờ, mỗi tầng đều có nhóm can thiệp và chứng. Sự tương quan/kết hợp giữa hai biến độc lập và phụ thuộc được tính riêng biệt giữa các tầng và được so sánh với sự tương quan/kết hợp chung (không phân tầng). Đương nhiên không sử dụng trắc nghiệm thống kê trong so sánh này. Nếu yếu tố nhiễu đang nghi ngờ không phải là một nguyên nhân trung gian (intermediate cause) thì sự khác biệt trong so sánh trên chính là nhiễu gây ra.
Ví dụ, vẫn là nghiên cứu tác dụng của thuốc A trong điều trị bệnh gout tại quần thể người bị gout thuộc huyện M. Nếu giả sử thu nhập là một yếu tố được nghi ngờ là nhiễu (thu nhập càng cao thì ăn uống càng nhiều đạm, do vậy tỉ lệ điều trị không khỏi bệnh gout cao), mặt khác thuốc A là thuốc đắt tiền nên thường chỉ có người có thu nhập cao mới dám dùng thuốc này. NCV chia quần thể nghiên cứu thành 04 tầng theo thu nhập như sau:
Tầng 1: Thu nhập trung bình đầu người/tháng: Từ 30 triệu đồng trở lên;
Tầng 2: Thu nhập trung bình đầu người/tháng: Từ 10 triệu đến < 30 triệu;
Tầng 3: Thu nhập trung bình đầu người/tháng: Từ 05 triệu đến < 10 triệu;
Tầng 4: Thu nhập trung bình đầu người /tháng: < 5 triệu.
Bây giờ ta tính riêng rẽ OR (sự kết hợp giữa sử dụng thuốc A và giảm bệnh gout) cho mỗi tầng, được kết quả như sau:
Tầng 1: Giá trị OR tính được là: 1,2
Tầng 2: ……………………….: 1,6
Tầng 3:………………………..: 1,65
Tầng 4: …………………………1,7
Toàn quần thể (chung)…………1,63
Nhận định: Phân tầng đã loại những người có thu nhập cao ra (tầng 1) nên giá trị OR của các tầng khác là ước lượng khá đúng cho sự kết hợp giữa dùng thuốc A và giảm bệnh gout. Độ lớn của nhiễu vào khoảng -0,35 (lấy 1,2 – 1,4 hay 1,65 hay 1,7), theo chiều hướng âm, tức làm tăng việc điều trị không khỏi bệnh gout là khoảng 35%.
3.5. Kĩ thuật khác: Kĩ thuật chuẩn hóa (Standartdization), kĩ thuật phân tích đa biến (Multivariate analysis)…phức tạp nên không có điều kiện đi sâu ở đây.
Chú thích
[1] Bias as defined as ‘any effect at any state of investigation or inference tending to produce results that depart systematically [i.e. one-sidely] from the true value’.
Tài liệu tham khảo
- J.H. Abramson () “Interpreting the findings”, Survey method in community medicine – Epidemiological Studies, Programe Evaluation, Clinical Trail, Fourth edition, Churchill Livingstone, p.159, 246, 256.
- Vũ Khắc Lương (2003) “Chương 3. Đối tượng và phương pháp nghiên cứu”, Nghiên cứu cải tiến tổ chức và quản lý khám chữa bệnh ngoại trú tuyến y tế cơ sở ngoại thành Hà Nội, Luận án Tiến sĩ Y học, Trường Đại học Y Hà Nội, trang 116.
- Trần Thái Hà (2012), Nghiên cứu bài thuốc “Thân thống trục ứ thang”trên thực nghiệm và tác dụng điều trị hội chứng thắt lương hông do thoát vị đĩa đệm, Luận án Tiến sĩ Y học chuyên ngành Y học cổ truyền, mã số 62.72.60.01, Trường Đại học Y Hà Nội, Thư viện Quốc gia Việt Nam, http://luanan.nlv.gov.vn/luanan?a=d&d=TTcFlGvGTmfy2012&e=-------vi-20--1--img-txIN------- , cập nhật 13-2-2020.
- Dương Đình Thiện, Lê Vũ Anh, Nguyễn Trần Hiển, Trần Tuấn (1993) “Các loại sai số”, Dịch tễ học Y học, Nhà xuất bản Y học, trang 224, 238, 239.
- Nguyễn Văn Tuấn (2019) Tóm tắt đề tài: Đánh giá hiệu quả của “Doctor SAMAN – Khít khao” trên lâm sàng, trang web của Viện Y học bản địa Việt Nam, https://yhocbandia.vn/tom-tat-de-tai:-danh-gia-hieu-qua-cua-doctor-saman-khit-khao-tren-lam-sang.html, cập nhật 13-3-2020.
- R Bonita, R Beaglehole, T Kjellstrom () Dịch tễ học cơ bản, Worldhealth Organization, Bản tiếng Việt, xuất bản lần 2, Dịch giả: Trần Hữu Bích, Lã Ngọc Quang và cs, trang số 58-59.
Doctor SAMAN
Vũ Khắc Lương
Phó giáo sư, Tiến sĩ Y học, Giảng viên cao cấp Trường Đại học Y Hà Nội
![[Nghiên cứu về thuốc giảm đau] Khái niệm về đau](/yhbd.vn/upload/images/2013/01/kiem%20soat%20dau.jpg)